Blog
Dark Matter
Posted on January 26, 2021
I've had an interest in physics for a long time now. During my childhood, my father worked at Fermi National Accelerator Laboratory and I would occasionally visit the lab. It was inspiring to see all of the large-scale science experiments, especially the Tevatron, a 6.28 kilometer circumference particle accelerator ring used to discover subatomic particles. Surely being exposed to concepts like particle physics so young left a lasting impression on me. I find physics interesting in the way that it dictates the fundamental laws of nature. There is a desire to think, if we could only map out all of the laws of nature, then we would know the absolute limits of what technology is capable of. Of course, reality often falls short of this desire. Quantum mechanics is probabilistic in nature, and we know that in many cases at very small scales it is impossible to know the state of things without measuring it and changing the outcome (collapsing the wave function). Likewise, there are still many unsolved problems in physics including the search for an understanding of what dark matter and dark energy is.
Lately when it's late at night and I'm in the mood to learn I've been putting on YouTube videos by this theoretical physicist Brian Greene. Anyway, if you have any interest in getting a deeper understanding of dark matter, without getting into any math, this discussion among four experts I found to be quite interesting. In particular, it was helpful at explaining why most people believe dark matter is a kind of matter, instead of an effect of gravity behaving differently at different scales and distances.
Bootable USB With Persistence
Posted on January 20, 2021
This post is about how to create a bootable USB drive that runs Ubuntu Linux and can store data persistently. The next few paragraphs however explain why I am doing this. If you are reading this and only interested in the "how" but not the "why" then please skip directly to the instructions below.
For the last few months, I have been working sporadically on a side project where I am writing software that performs a "quadratic field sieve" (QFS) algorithm. The goal of the exercise is to write some code that uses true parallelism to achieve result more quickly than a single thread of execution would. I simply looked up parallel algorithms on Wikipedia and found the one that was most interesting to me, in this case a number-factoring algorithm that can be used to crack encryption.
Understanding the algorithm itself required reading several different whitepapers and thesis papers people had written about it, because although information on the QFS algorithm is plentiful, most of the explanations are somewhat superficial and do not cover the level of detail required in order to have a successful implementation. In some places, information is just simply wrong.
Things were going well. I had implemented a simplified non-parallel version of the first half of the algorithm (the sieving part). In order to do a proof of concept I needed to finish the second part of the algorithm, which when complete will involve solving very large sets of matrix equations. Since this was a well-understood mathematical problem, I chose to seek out a software library for this part since it's often faster and wiser to use an already working library, than to re-invent the wheel. It was at this point where I ran into problems. I located an algorithm on github that was written in C++ and therefore compatible with the same complier I was using for my C++ code, but upon further inspection I realized it used Nvidia's CUDA which uses a graphics card rather than a CPU. Although I have a graphics card, I run my Linux distribution within a VirtualBox (free) VM, and this VM does not allow me to access the graphics card directly. This is where I got the idea of using a USB drive to boot to a live distribution of Linux along with some kind of persistent storage to save my work. This would allow me to run Linux, access my graphics card, and run the library, without having to worry about dual booting, or buying a more expensive set of virtualization software to access the GPU.
Therefore, without further ado, here is one way to create a USB drive running a live distribution of Linux that has persistent storage circa 2021. This instructions are for Windows.
Instructions
For simplicity I am going to assume your USB drive is mounted as the E: drive, although this may vary.
- Go to https://ventoy.net/en/download.html
- Download and install the latest version of ventoy for Windows
- Insert a USB drive you plan on using
- Execute Ventoy2Disk.exe and click "Install"
- Confirm twice that you are aware you are about to format the drive
- Using Windows Explorer create the following directory structure on the USB drive
- Using your favorite text editor in the ventoy directory create a json file named "ventoy.json" and add the following content to it:
- Download this zip here https://github.com/ventoy/backend/releases/download/v3.0/images.zip and unzip it (this may be slow), and then pick a compatible .dat file. In my case I chose "persistence_ext4_4GB_casper-rw.dat.7z" because I was planning on using Ubuntu and Ubuntu requires are label of "casper-rw". Unzip the z-zip directly into E:\persistence.[1]
- Download the .iso of the live Linux distribution you are planning on using and put that under E:\iso
- Rename your files however you like and ensure that file files names in ventoy.json exactly match the file names under /iso and /persistence. In this case I went with "ubuntu-20.04.1-desktop-amd64.iso" for the ISO and "ubuntu_20.04_ext4_4GB_casper-rw_persist.dat" for the persistence file where the persistent files are stored.
- Done. Reboot and make sure to select the USB drive in the boot menu.
iso/ persistence/ ventoy/
{
"persistence": [
{
"image" : "/iso/ubuntu-20.04.1-desktop-amd64.iso",
"backend" : "/persistence/ubuntu_20.04_ext4_4GB_casper-rw_persist.dat",
"autosel" : 1
}
]
}
Footnotes
[1] - If you have a Linux box you can mount your USB and create your own larger .dat file using the CreatePersistentImg.sh script found here. Personally, I was having issues with VirtualBox not keeping the USB drive mounted for long enough to generate a large 100GB .dat file, so I ultimately settled on using the 4 GB image above.
What is the Volume of a Donut?
Posted on July 13, 2019
A couple of colleagues of mine at Panasonic like to keep work fun and write random programming challenges on a whiteboard for anyone to solve. This challenge is from Ken and isn't a programming question but is an interesting question nonetheless: What is the volume of a donut? ... Finally! An excuse to use my LaTeX JavaScript library.
At first it seems like one should be able to come up with some quick formula such as calculating the volume of a cylinder with the same length as the circumference of the donut at it's center. If that was the case then it would simply be the area of a circular cross section of the donut \(\pi r^2 \) times the length of the donut at it's center \(L = 2 \pi R \) which when multiplied together yields the volume of the donut \(V_{d}=2\pi^2rR\). However, while intuition may say this seems correct, intuition is not proof, and the whole idea relies on the assumption that the volume on the inside removed when forming the donut and is perfectly balanced by the volume added on the outside. The only solution that seems 100% foolproof is to use an integral to integrate over the shape of the donut somehow.
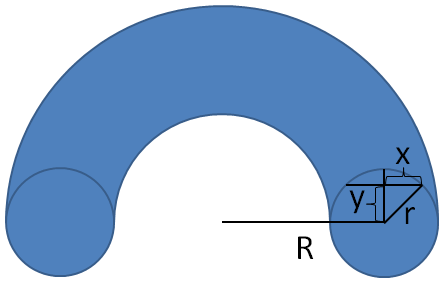
After several attempts to examine the symmetry (and let's be honest a quick google search) I decided that the "washer method" was probably the simplest way to integrate over the donut. The method relies on slicing the donut horizontally and forming little "washers".
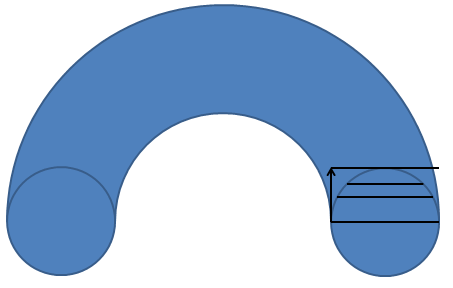
The area of a washer \(A_w\), is easy to calculate. It's the area of a circle formed at the outer diameter minus the area of the circle that forms the hollow part in the center. We could say \(A_{w}=\pi R1^2 - \pi R2^2\), where \(R1=R+x\) and \(R2=R-x\). In other words: \(A_{w}=\pi ((R+x))^2 - (R-x))^2)\)
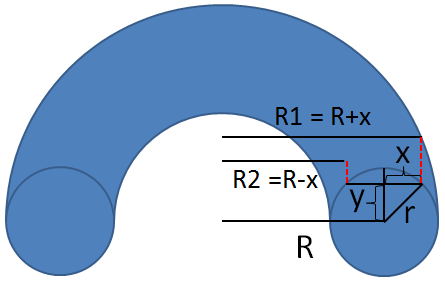
The problem with this formula is that we have it in terms of the variable \(x\) when we want to integrate in the \(y\) direction, so we need to use the Pythagorean Theorem to re-write \(x\) in terms of \(y\) (and \(r\) which is constant). \[r^2=x^2+y^2\] \[y=\sqrt{r^2-x^2}\] \[x=\sqrt{r^2-y^2}\]
Substituting in the formula for \(x\) in terms of \(y\), we get:
\[A_{w}=4\pi R\sqrt{r^2-y^2}\]Now that we have the area of the washer formula, we need to integrate over \(y\) from the center where \(y\) is zero to the edge of the donut where \(y=r\). And since that will only yield half of the volume of the donut, we need to multiply the whole equation by 2. Therefore we have
\[V_{d}=8\pi R\int_{y=0}^{y=r}\sqrt{r^2-y^2}dy\]I would love to tell you this is where I busted out my amazing memory of calculus that I learned 17 years ago and went to town on the destroying this integral, but that would be a lie. What really happened is I searched google for a refresher on integration by parts and U-substitution, but after that I still couldn't solve it. Then I straight up searched google for the answer to this problem, and I found a couple of sites and videos that solved the integral, but after looking at the answer in front of my face I still didn't understand it. So that's when I called in the big guns and asked my friend from high school, Aaron Hedlund a Ph.D Economist who can leg press 800 lbs. and eats integrals for breakfast, to take a look. Incidentally he was traveling at the time, so he did his best attempt to pull a Guido Menzio however was too waspy to arouse any suspicions at the time. I will explain the rest of the solution in my own voice but from this point forward Aaron is due credit for the rest of the solution.
Since \(r\) is a constant it can be pulled out of the integral so instead of solving the original integral we will first focus on solving a similar but different integral, which will then be useful at the end when performing U-substitution to solve the original integral. The integral we will work on is the indefinite integral
\[\int\sqrt{1-y^2}dy\]To solve this we need to take advantage the trigonometric identity
\[cos(\theta)^2+sin(\theta)^2 = 1\]Rearranging a little
\[cos(\theta)^2=1-sin(\theta)^2\]We get
\[cos(\theta)=\sqrt{1-sin(\theta)^2}\]From here we can make a substitution in the indefinite integral
\[\text{let}\hspace{3mm}y=sin(\theta)\] \[\text{and}\hspace{3mm}dy=cos(\theta)d\theta\]so that
\[\int \sqrt{1-y^2}dy \rightarrow \int cos(\theta)cos(\theta)d\theta\] \[=\int cos^2(\theta)d\theta\]Now we need another trigonometric identity
\[cos^2(\theta)=\frac{1}{2}+\frac{cos(2\theta)}{2}\]Substituting yet again we get
\[\int cos^2(\theta)d\theta \rightarrow \int \frac{1}{2}+\frac{cos(2\theta)}{2}d\theta\]
Now finally we have an integral that I can solve. Integrals distribute across addition so we can solve each part independently. The integral of a constant with respect to \(\theta\) is just the constant times \(\theta\), and reversing the chain rule for the integral of \(cos(2\theta)\) is relatively easy. Since the derivative of \(sin(2\theta)\) is \(cos(2\theta)*2\) we divide by two when reversing it. Therefore \[\int \frac{1}{2}+\frac{cos(2\theta)}{2}d\theta = \frac{\theta}{2}+\frac{1}{2}\frac{sin(2\theta)}{2}+c\]
Then using yet another trigonometric identity
\[sin(2\theta) = 2sin(\theta)cos(\theta)\]The solution becomes
\[\frac{\theta}{2}+\frac{1}{2}sin(\theta)cos(\theta)+c\]Using our previous identity \(cos(\theta)=\sqrt{1-sin(\theta)^2}\) we can rewrite the equation as
\[\frac{\theta}{2}+\frac{1}{2}sin(\theta)\sqrt{1-sin(\theta)^2}+c\]Earlier when we substituted to re-write the equation in terms of \(\theta\) rather than \(y\) we let \(y = sin(\theta)\) therefore \(\sin^{-1}(y)=\theta\) so that if we substitute this back in to remove the \(\theta\) and re-write the solution in terms of \(y\) the previous solution becomes \[\frac{sin^{^{-1}}(y)}{2}+\frac{1}{2}sin(sin^{^{-1}}(y))\sqrt{1-(sin(sin^{^{-1}}(y)))^2}+c\]
Simplifying we get
\[\frac{sin^{^{-1}}(y)}{2}+\frac{1}{2}y\sqrt{1-y^2}+c\]So in summary, we now know that
\[\int \sqrt{1-y^2}dy=\frac{sin^{^{-1}}(y)}{2}+\frac{1}{2}y\sqrt{1-y^2}+c\]Now remember way back earlier when I said since \(r\) is constant it can be pulled out of the original integral we are trying to solve? No? Well me neither, so scroll back up and re-read everything until it makes sense and come back here where we will use the pull-out method. Err, I mean we will pull \(r\) out of our original integral.
\[\int \sqrt{r^2-y^2}dy=\int \sqrt{r^2(1-(\frac{y}{r})^2)}\] \[=r\int \sqrt{(1-(\frac{y}{r})^2)}dy\]Things are looking pretty good here. In fact this integral looks almost exactly like the similar one we already solved! All that remains is that we perform U-Substitution, and evaluate the solution at the limits and we're done.
\[\text{let}\hspace{3mm}u = \frac{y}{r}\] \[\text{and}\hspace{3mm}du = \frac{1}{r}dy\]So that
\[dy=rdu\]Performing U-Substitution we get
\[r\int \sqrt{(1-(\frac{y}{r})^2)}dy\rightarrow r\int{\sqrt{1-u^2}}rdu\] \[=r^2\int{\sqrt{1-u^2}}du\]All that is left now is to use our solution to the indefinite integral from earlier and evaluate it at the integral limits. We have to re-write the integral limits in terms of \(u\) rather than \(y\) however, this is very simple since at \(y=0\), \(u=0\) and at \(y=r\), \(u=1\). Therefore our limits are from \(u=0\) to \(u=1\)
\[V_{d}=8\pi R\int_{y=0}^{y=r}\sqrt{r^2-y^2}dy\] \[=8\pi Rr^2\int_{u=0}^{u=1}\sqrt{1-u^2}du\] \[=8\pi Rr^2 \left ( \left [ \frac{sin^{^{-1}}(1)}{2}+\frac{1}{2}1\sqrt{1-1^2} \right ] - \left [ \frac{sin^{^{-1}}(0)}{2}+\frac{1}{2}0\sqrt{1-0^2} \right ] \right )\] \[=8\pi Rr^2 \left ( \left [ \frac{1}{2}\frac{\pi}{2}+0 \right ] - \left [ 0+0 \right ] \right )\] \[=8\pi Rr^2 \left ( \frac{\pi}{4} \right )\] \[=2\pi^2 Rr^2 \]The solution is of course somewhat humorous given that it was a total pain in the ass to prove what we already suspected was the correct answer from intuition.
Reinventing the Wheel
Posted on April 2, 2019
Back in 2010 I finished my Master's degree from USC and I was looking for a new job. I landed an interview with a certain company that engages in space exploration and has a CEO whose last name sounds like it is a men's cologne. As part of the interview they had a programming challenge with a six hour time limit. The programming problem itself required a sort to be done, and explicitly stated it must be done in at worst O(n log n) time. They told me I could not use any C++ standard libraries, but I could use any code I had written myself.
This of course was frustrating, bullshit really, since even though I had taken all of the data structure courses in undergrad and again in graduate school, I did not save any code. Why would I? It's not a good idea to use your own home brew data structures. The ones provided by standard libraries are widely used and thoroughly debugged. People are already familiar with them, which makes code written with them easy to understand. Their implementations have been so widely deployed they are highly unlikely to contain errors.
Ultimately I ended up writing my own min-heap from scratch and solving the problem, but not within the time limit, meaning I did not advance in the job interview. Call it immaturity, or more accurately spite, but later I went back and decided to make my own equivalent implementations of most of the C++ STL container classes.
My implementation is mostly complete; however some of the more complex features have been omitted. At a certain point I realized spending any more time to get all of the details finalized is just a fool's errand. Anybody who wants you to use your homebrew data structures over the standard library versions is not good at their job and probably not somebody you want to work with.
I understand the purpose of the interview question was to prove that you knew how to implement efficient data structures, but if this was the purpose it was silly for them to allow people to reuse old code, since that puts the class of people who just happened to save their old code at a HUGE advantage over other good people that understand why it is wise to use standard libraries. Additionally, just because you implemented something in the past, doesn't mean you still know how to do it today.
Anyway if you want to see me reinvent the wheel the code is here on github.
Birthday Brewing
Posted on May 10, 2018
 One of my favorite hobbies is brewing beer. After a long hiatus I finally managed to find some time on my birthday to brew my favorite kind of beer, the incredibly strong, lightly hopped, super delicious Belgian Tripel. Don't get me wrong, I love the fact that craft brewing has taken off, but beers now days are just too damn bitter. I mean super bitter. I'm talking about 120 minute IPAs with IBU numbers pushing over 100. But I guess such is the price you pay for living in the United States, where for whatever reason many Americans just like to take things to the extreme. To me the Belgian Tripel is the ideal beer. It's got a high enough ABV at around 10% where there's no chance that the effects of alcohol dehydrogenase will prevent you from getting a buzz, but not so strong that the ethanol aroma must be masked by copious amounts of hops or malt. The Belgian style yeast, which of course is part of what makes it a Belgian frequently imparts some fruity aromas like banana or oranges and often a hint of cloves, a la another great beer Franziskaner.
One of my favorite hobbies is brewing beer. After a long hiatus I finally managed to find some time on my birthday to brew my favorite kind of beer, the incredibly strong, lightly hopped, super delicious Belgian Tripel. Don't get me wrong, I love the fact that craft brewing has taken off, but beers now days are just too damn bitter. I mean super bitter. I'm talking about 120 minute IPAs with IBU numbers pushing over 100. But I guess such is the price you pay for living in the United States, where for whatever reason many Americans just like to take things to the extreme. To me the Belgian Tripel is the ideal beer. It's got a high enough ABV at around 10% where there's no chance that the effects of alcohol dehydrogenase will prevent you from getting a buzz, but not so strong that the ethanol aroma must be masked by copious amounts of hops or malt. The Belgian style yeast, which of course is part of what makes it a Belgian frequently imparts some fruity aromas like banana or oranges and often a hint of cloves, a la another great beer Franziskaner.
This post is not about how to make all-grain beer. For that I refer you to the legendary John Palmer's site www.howtobrew.com.
 Here's the recipie:
Here's the recipie:
- 12 lbs. Rahr Premium Pilsner Malt
- 0.25 lbs. Belgian Aromatic Malt
- 0.5 lbs. Dingemans Cara 20 Malt
- 2 lbs. Light Belgian Candi Sugar
- 0.75 oz. Styrian Goldings (3.3% AA) hops for 60 minutes
- 0.25 oz. Stryian Goldings (3.3% AA) hops for 5 minutes
- 15 grams home grown Chinook Hops (12-14% AA) hops for 60 minutes
- 5 grams home grown Chinook Hops (12-14% AA) hops for 5 minutes
- 1 lb. orange peel for 5 minutes
- 1 Whirflock tablet for 5 minutes
The Chinook hops weren't part of the original recipie, but they're what my hop garden produced and I wanted to use them. It's too bad I'm not doing something like a Sierra Nevada IPA or a Dale's Pale Ale since then I think it might make sense to give dry hopping a try, but with a Belgian I think that's a big no-no. The beer is still fermenting so I don't know the final ABV but it measured an O.G. of 1.081 so it should be able to hit 9% easy.
The James Webb Space Telescope
Posted on August 19, 2017
About a year or so ago I learned about the James Webb Space Telescope. The telescope is part of collaboration between NASA, the European Space Agency, and the Canadian Space Agency. It's named after James Webb a soon-to-be-famous NASA administrator that played an important role in the Apollo missions. What sets it apart from the Hubble telescope is its mirror, planned orbit, and instrumentation.
 The mirror is one of the things that make the telescope so darn awesome. Since launching payloads up into space is very expensive, size and mass are both very constrained, and since the diameter of the rocket payload is fixed, satellites often rely on folding mechanisms such as solar panels that expand. That's where the mirror comes in. Instead of being made of one circular mirror limited to the diameter of the rocket, it's made of 18 hexagonal mirror segments that unfold and combine into one giant mirror. If that wasn't cool enough the engineers over at NASA decided to coat the mirrors in fucking gold. I had assumed the gold was so NASA could use up their remaining annual budget so it wouldn't get cut the next year as punishment for being efficient, but it turns out that the microscopic gold layer improves the mirrors ability to reflect infrared light.
The mirror is one of the things that make the telescope so darn awesome. Since launching payloads up into space is very expensive, size and mass are both very constrained, and since the diameter of the rocket payload is fixed, satellites often rely on folding mechanisms such as solar panels that expand. That's where the mirror comes in. Instead of being made of one circular mirror limited to the diameter of the rocket, it's made of 18 hexagonal mirror segments that unfold and combine into one giant mirror. If that wasn't cool enough the engineers over at NASA decided to coat the mirrors in fucking gold. I had assumed the gold was so NASA could use up their remaining annual budget so it wouldn't get cut the next year as punishment for being efficient, but it turns out that the microscopic gold layer improves the mirrors ability to reflect infrared light.
 Another thing that makes the Webb cool is where it will be orbiting in space. The telescope is going to be at the Earth-Sun L2 Lagrangian point. This is a point further from the sun than earth, where the gravity from the sun and the earth add together allowing an object to orbit the sun faster than in normally would, keeping it orbiting at the same rate as the Earth. This means objects in the L2 point will always be in the shadow of the earth, something particularly useful if you're building a space telescope. The downsides to that point are that it's quite far away (about 4x as far as the moon), which will make the unserviceable if something goes wrong, and it's an unstable point, so the telescope will need to take fuel with it to stabilize and maintain its orbit. Eventually, after 10 years or so the telescope will run out of fuel and will begin to drift away from the L2 point.
Another thing that makes the Webb cool is where it will be orbiting in space. The telescope is going to be at the Earth-Sun L2 Lagrangian point. This is a point further from the sun than earth, where the gravity from the sun and the earth add together allowing an object to orbit the sun faster than in normally would, keeping it orbiting at the same rate as the Earth. This means objects in the L2 point will always be in the shadow of the earth, something particularly useful if you're building a space telescope. The downsides to that point are that it's quite far away (about 4x as far as the moon), which will make the unserviceable if something goes wrong, and it's an unstable point, so the telescope will need to take fuel with it to stabilize and maintain its orbit. Eventually, after 10 years or so the telescope will run out of fuel and will begin to drift away from the L2 point.
Unlike the Hubble which was originally a visible light telescope, the Webb is an infrared telescope. Due to red shift from the ever increasing expansion of space, the light from the earliest days of the universe is no longer in the visible spectrum; instead it has shifted into the infrared portion of the spectrum. Because of this the Webb has been fitted with four different kinds of infrared instruments. The Webb will allow us to see into the past further than we ever have before to gain a better understanding about the origins of the universe. Here's to hoping the mission goes off without a hitch. The telescope is scheduled to launch in October 2018.
Troubleshooting The Linux Firewall By Inserting A Trace Rule
Posted on February 11, 2017
If you are having trouble figuring out whether or not a packet is being dropped by the Linux firewall there is a way to trace the path a packet takes. It does require some knowledge of the ports and protocols involved as well as the ability to make iptables rules. The basic idea is that traffic leaving a Linux box directly, or being routed through it will hit a special table called the "raw" table first where users can put in trace rules. If the traffic is leaving the box directly the rule is added to the "OUTPUT" chain of the "raw" table. If the traffic is being routed through the box then the rule is added to the "PREROUTING" chain of the "raw" table. The general format is
# For traffic being routed through the box
user@linux# iptables -t raw -A PREROUTING [ RULE TO DETECT DESIRED TRAFFIC ] -j TRACE
# For traffic that originates from the box itself
user@linux# iptables -t raw -A OUTPUT [ RULE TO DETECT DESIRED TRAFFIC ] -j TRACE
Please note: Adding trace rules can add a very heavy burden on the kernel and can impact performance and potentially the stability of the system. They are for troubleshooting purposes only. Trace rules should always be deleted immediately after are done! To delete a rule you inserted simply change the -A for append to -D for delete.
Most of the time the kernel will not be built with the trace modules included by default. If they are not already present you can use modprobe to install the logging modules. Here are some examples:
# For older kernels.
user@linux# sudo modprobe ipt_LOG
# For newer kernels.
sudo modprobe nf_log_ipv4
# Trace TCP traffic leaving the Linux box
user@linux# iptables -t raw -A OUTPUT -p tcp --dport 80 -j TRACE
# Trace TCP traffic returning to the Linux box
user@linux# iptables -t raw -A PREROUTING -p tcp -sport 80 -j TRACE
The logs themselves will appear in /var/log/kern.log. Here are some sample logs I collected while connecting to www.google.com with wget:
Feb 11 10:41:13 ubuntuvm kernel: [ 4199.166329] TRACE: raw:OUTPUT:policy:2 IN= OUT=eth0 SRC=192.168.1.2 DST=216.58.193.196 LEN=60 TOS=0x00 PREC=0x00 TTL=64 ID=37314 DF PROTO=TCP SPT=42240 DPT=80 SEQ=3750653972 ACK=0 WINDOW=29200 RES=0x00 SYN URGP=0 OPT (020405B40402080A000EE1D60000000001030307) UID=0 GID=0 Feb 11 10:41:13 ubuntuvm kernel: [ 4199.182926] TRACE: raw:PREROUTING:policy:2 IN=eth0 OUT= MAC=08:00:27:2e:a1:89:00:90:7f:91:68:b4:08:00 SRC=216.58.193.196 DST=192.168.1.2 LEN=60 TOS=0x00 PREC=0x00 TTL=56 ID=31143 PROTO=TCP SPT=80 DPT=42240 SEQ=1985453739 ACK=3750653973 WINDOW=42540 RES=0x00 ACK SYN URGP=0 OPT (020405780402080A082895B6000EE1D601030307)
While this example clearly isn't very useful it should be enough to get most people going with tracing packets through the Linux firewall. The only thing you must know is how to write the correct trace rules for the traffic you are interested in. There is tons information in the blogosphere about Linux IPTables and how to write firewall rules, or you can just RTFM with "man iptables", and "man iptables-extensions".
Styled Math Inline HTML with LaTeX
Posted on January 23, 2017
The fact that it was so easy to get code styled inline HTML got me wondering what else could be quickly put together using a JavaScript library. What about complex math symbols? Another quick Google search and sure enough someone has already done something like this. In academia it's common for people to write whitepapers that have math symbols in them that are generated by compiling Tex or LaTeX markup. The MathJax library allows one to place Tex/LaTeX symbols inline an HTML document and to automatically generate pretty automatically formatted math symbols into a webpage. You just take the LaTeX and surround it with \[ and \] and it automatically gets converted into beautifully formatted math symbols. The LaTeX text below:
\[ \oint_C {E \cdot d\ell = - \frac{d}{{dt}}} \int_S {B_n dA} \]
becomes Faraday's law:
\[ \oint_C {E \cdot d\ell = - \frac{d}{{dt}}} \int_S {B_n dA} \]
Automatically Styled Code Inline HTML
Posted on January 21, 2017
I've always wondered how so many programming blogs have neatly formatted code examples. After doing a quick google search it turns out there's many existing options out there. The one in particular I used for the example below is called "SyntaxHighligther." The documentation over there is very well written and easy to follow. All that is required is to download 4 files, a couple of core CSS and JavaScript files, an additional CSS file for the theme, and a JavaScript file corresponding the programming language being used. Then simply add links to the JavaScript and CSS files in the head of your page, and apply the style inline (in my case "bush: cpp") to the <pre> tag and you're good to go.
class Rectangle {
int width, height;
public:
void set_values (int,int);
int area (void);
} rect;
Blog Goes Live
Posted on January 20, 2017
The goal here is to post whenever I have something of value that I think other people might find interesting.